
เขียนต่อจากเมื่อวานนี้ เพราะเดี่ยวคืนนี้ต้องบินไปเซี่ยงไฮ้ไปดูงาน CES Asia ซึ่งความจริงเมื่อต้นปีต้องไปงาน CES ที่ Las Vegas แต่ดันป่วยเอาซะก่อน เลยมาเก็บตกทางฝั่ง Asia ดูไม่งั้นเว้นไว้นานจะเขียนไม่ต่อเนื่องเอา
เล่าต่อจากเมื่อวานนี้ที่ผมเอาชุดข้อมูลขนาดประมาณ 700 ล้าน Record เพื่อไปประมวลผลหา Insight ของ Data โดยอาศัย Qlikview ซึ่งแทนที่จะซื้อเครื่องใหม่มา ก็ไปใช้บริการ VDI หรือ DaaS ของ Amazon ที่ชื่อว่า AWS Workspace แทน ซึ่งก็ตอบโจทย์ในเรื่องของ Remote Access, Resource Ondemand และ Performance
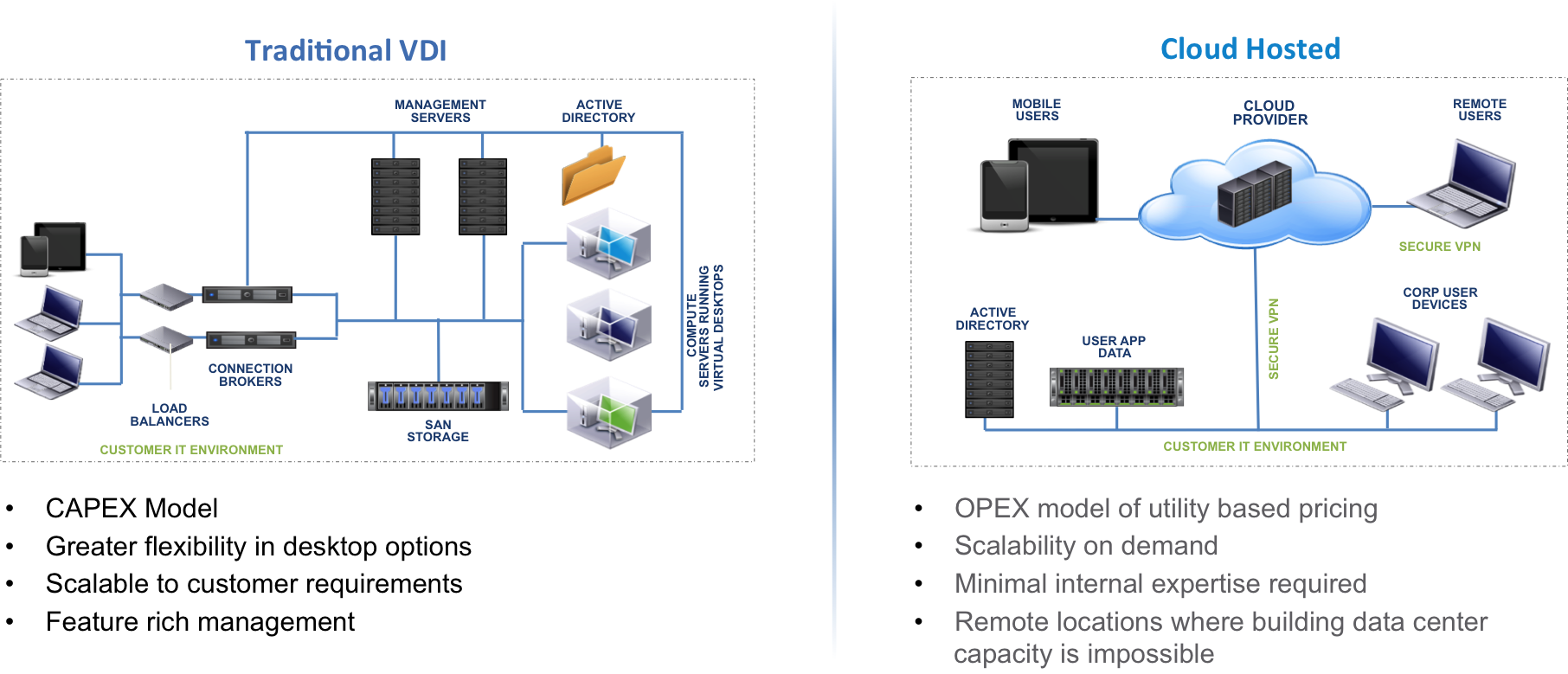
แต่ถ้าว่ากันในเรื่องของ Price หรือ Cost แล้ว ถ้าคิดตรงๆอาจไม่เหมาะสมแน่ๆ ซื้อเครื่อง PC ดีๆราคาประมาณ 3-5 หมื่นบาท หาร 12 เดือน ราคาถูกกว่าเช่า AWS Workspace แน่ๆ (8Vcore, 32GB Ram, 100GB SSD ผมจ่ายอยู่เดือนละประมาณ 170 USD) แต่ใน Project VDI หรือ DaaS แล้วสิ่งที่ต้องนำมาคิดเพิ่มก็คือ ค่า Opex ต่างๆไม่ว่าจะเป็นต้นทุนคนที่ต้องดูแล การ Backup ของข้อมูล ความเสี่ยงกรณีข้อมูลหาย ค่า Internet ต่างๆ ซึ่งโดยภาพรวมแล้วเมื่อรวมค่า Opex เหล่านี้เข้าไปจะทำให้การลงทุนในส่วนของ VDI นั้นช่วยลดต้นทุนในส่วนของ Opex ลงและเอา Resource ที่ต้องมาดูแล เดี่ยวๆก็ต้องไปคอยเปลี่ยน Ram สาขา, Update โปรแกรม, เพิ่ม Ram, เพิ่ม Hdd เอาไปทำงานพัฒนาอย่างอื่นที่มี Value มากกว่า ซึ่งจะลงทุนทำเอง หรือใช้บริการ Cloud VDI อย่าง AWS Workspace ก็ขึ้นกับงบประมาณ ความพร้อมของทีมดูแล และนโยบายของแต่ละบริษัทด้วย
เกริ่นออกนอกเรื่องไปพอประมาณจากข้อมูลที่ประมวลผลบน Qlikview ที่ทำงานบน AWS Workspace ก็ตอบโจทย์ที่ผมทำอยู่ในระดับหนึ่ง ถึงแม้บางรายงานอาจรอในการประมวลผลถึงสองนาทีก็ยังพอรับได้ แต่ดันมีข้อมูลอีกชุดประมาณ 5000 ล้าน Record ซึ่งถ้าโยนขึ้นไปทำงานบน Qlikview ตั้งแต่แรกมีอันจบกันแน่ คราวนี้จะทำยังไงกันดีหละ ก็เริ่มมองหา Solution ที่ทำงานเป็นลักษณะ as a service คือจ่ายเท่าที่ใช้ เพราะข้อมูลชุดนี้นิ่ง ไม่มีการเปลี่ยนแปลง ไม่มี Add Insert Delete Append ก็เลยมองไปทาง Google Cloud ซึ่งก็มีหลาย Solution ที่ตอบโจทย์ในเรื่องของ Cloud Data Analytic
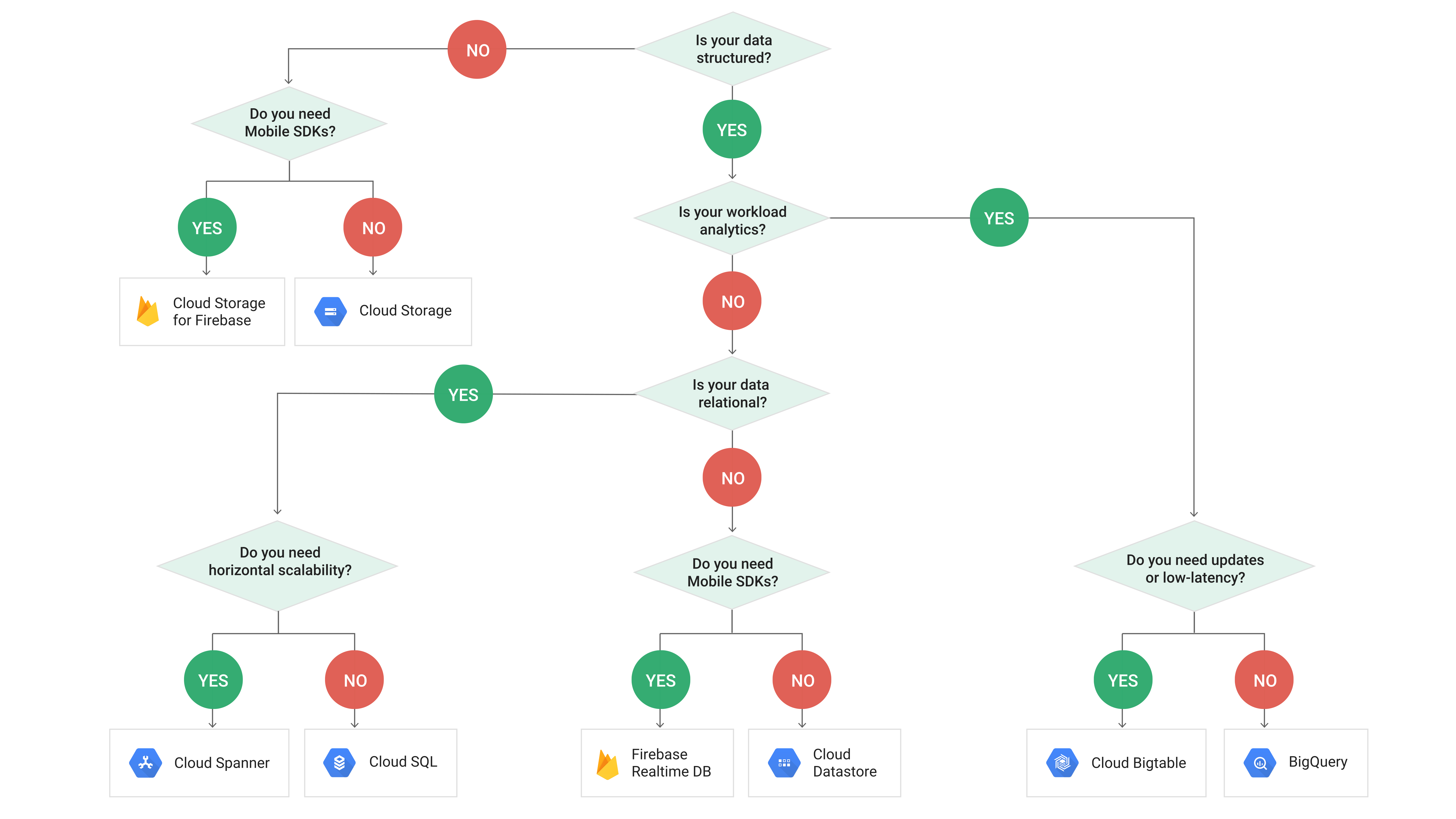
ในตอนแรกที่เลือกว่าจะใช้ Service ตัวไหนนั้นก็ค่อนข้างงงเหมือนกัน เพราะมีหลายตัวมาก Chart ด้านบนจะเป็นตัวตอบโจทย์ได้ดีทีเดียว ซึ่งข้อมูลของผมเป็นแบบ Structure และเน้นในเรื่องของ Analytic แต่การประมวลผลนั้นไม่ต้องการแบบ low-latency ฉะนั้นผมก็เลยมาจบที่ BigQuery
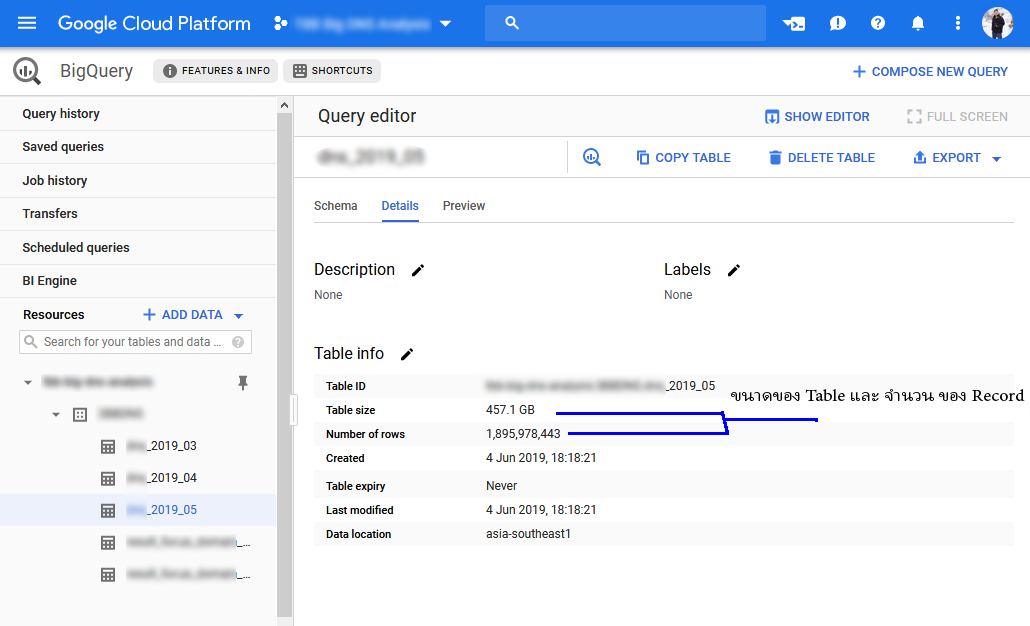
BigQuery คืออะไร มันก็คือเครื่องมือในการ Query ข้อมูล เขียนด้วยภาษา SQL ในการดึงข้อมูลที่เราต้องการขึ้นมา เพียงแต่ว่ามันประมวลผลข้อมูลจำนวนมากๆๆๆ ด้วยเวลาที่รวดเร็วมากๆๆๆๆ ประมวลผลเร็วขนาดไหน เดี่ยวเราลองมาดูกัน แต่ก่อนที่จะไปทดลองประมวลผลนั้น สิ่งที่เราต้องมีก็คือ Data ของเรานั่นเอง คราวนี้เราจะเอา Data มาจากไหนได้บ้าง
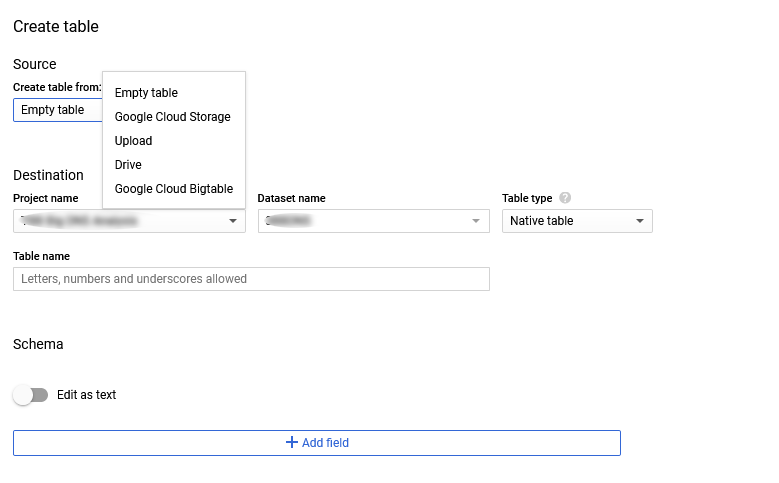
เมื่อเราสร้าง Data Set ขึ้นมาแล้ว ขั้นตอนต่อไปก็คือการสร้าง Table และ Import Data ในขั้นตอนนี้แหละครับเราจะเห็นได้ว่า เราสามารถเลือกการ Import Data ได้มาจากทั้ง Google Cloud Storage, Upload, Google Drive หรือ Google Cloud BigTable แล้วเราจะใช้ตัวไหนดี
- Upload ทีละไฟล์ ไฟล์ขนาดใหญ่คงไม่ไหว เพราะข้อมูลผมแตกออกมาเป็นหลายไฟล์มาก
- Drive อันนี้ก็ข้าม เพราะข้อมูลแค่หนึ่งวันก็ปาเข้าไป 12GB แล้ว ถ้าโหลดทั้งเดือน Google Drive ที่ใช้อยู่เต็มแน่นอน
- เหลือตัวเลือกสองตัวคือ BigTable กับ Cloud Storage ก็ย้อนกลับไปดูชาร์จก่อนหน้านี้ ข้อมูลผมนิ่งๆ ไม่ต้องการประมวลผลแบบ low-latency ใช้แค่เป็นถังพักข้อมูลเพื่อส่งต่อให้กับ BigQuery ฉะนั้นก็ผลก็เลยมาออกที่ BigTable นั่นเอง
ทุกอย่างดูดีหมด แต่มีอะไรบ้างที่เราต้อง Tradeoff กับบริการสุดไฮโซด้วยการประมวลผลข้อมูลจำนวนมหาศาลอย่างรวดเร็ว แน่นอนว่าเรื่องของ Security ข้อมูลควรมีการทำ Data Masking ก่อน เช่นข้อมูลลูกค้าจริงคือ ID001 ก็ทำการ Masking เป็น IDA0001 เป็นต้น เผื่อข้อมูลหลุดไปข้อมูลที่ Sensitive จริงๆจะได้ไม่หลุดไปด้วย และราคาที่ต้องจ่าย ที่ผมขีดเส้นใต้ในรูปของปริมาณของข้อมูลที่มีจำนวน Record นั่นแหละครับ
ถ้าเคสของผมที่เลือก Node เป็น Singapore โดยที่ในแต่ละเดือนนั้นจะได้ Free Quota ที่ 1TB แต่ถ้า Query ข้อมูลที่เกินจากนั้น ก็จะโดนอยู่ที่ TB ละ 10.75 USD จะว่าแพงก็แพง จะว่าไม่แพงก็ไม่แพง ขึ้นกับว่าเราใช้ประโยชน์จากข้อมูลนั้น หรือเอาข้อมูลนั้นไม่ทำอะไรต่อ และด้วยราคาขนาดนี้ ถ้าไม่ต้อง Implement Server, Network, Storage เองแล้วหละก็ สำหรับผมเองมองว่าคุ้มมาก
โม้ไว้ซะเยอะ คราวนี้เรามาลอง Run Query จาก 3 Table ที่มีข้อมูลประมาณ 5 ล้าน Record กัน ซึ่งคำสั่งที่ใช้งานก็เหมือน SQL ทั่วไป โดยเมื่อเขียนคำสั่งเสร็จก่อน Run เจ้าระบบ BigQuery ก็จะคำนวนมาให้เบ็ดเสร็จเลยว่าการประมวลผลข้อมูลนี้นี้มีปริมาณขนาดไหน
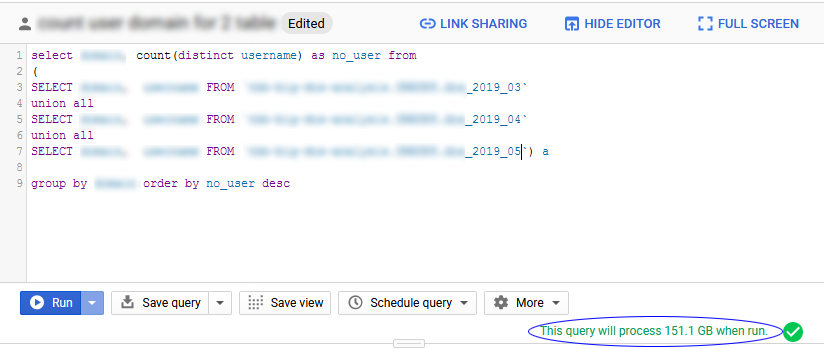
ซึ่งตรงนี้ก็เหมือนสมัยยุคกล้องฟิลม์แหละครับ ก่อนจะถ่ายต้องคิดแล้วคิดอีกจัดวางองค์ประกอบดีมั้ย ตั้งค่ากล้องถูกมั้ย แต่พอมายุคของการใช้งาน BigQuery ก็ต้องคิดเหมือนกัน เขียน SQL ครบมั้ย Field ที่จะดึงข้อมูลครบมั้ย Join Table ถูกหรือเปล่า เพราะเมื่อคุณใช้งานการประมวลผลเกิน 1TB ทุกๆ 10MB นั้นจะถูกนำมาคำนวนและคิดตังค์แล้วครับ
หลังจากที่กด Run แล้วระบบก็จะเริ่มประมวลผลให้เรา เมื่อประมวลผลเสร็จก็จะบอกเสร็จสรรพว่า ใช้เวลาไปเท่าไหร่ อย่าง SQL ง่ายๆข้างบนของผมก็ Query complete (38.2 sec elapsed, 151.1 GB processed) จากข้อมูล 5000 ล้าน Record ถือว่าใช้งานได้เลยทีเดียว และผลลัพท์ของการ Query นั้นก็สามารถ Export ไปได้หลากหลายรูปแบบ
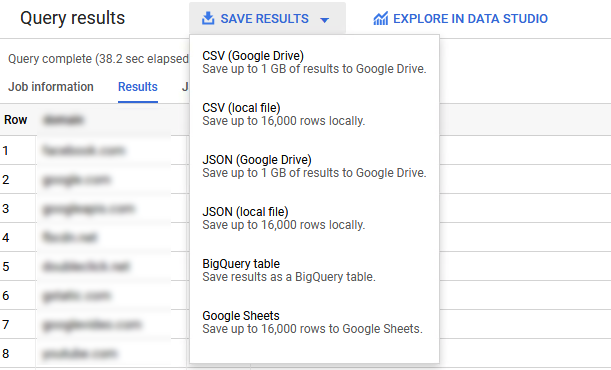
แต่โดยส่วนตัวที่ใช้ ก็จะมีส่งต่อไปยัง Google Drive กรณีที่ผลของข้อมูลไม่ใหญ่มาก เสร็จแล้วค่อยไปโหลดต่อบนเครื่องอื่น หรือแชร์ให้เครื่องอื่นทำงานต่อ หรือไม่ก็ Save ลงใน BigQuery Table เผื่อประมวลผลต่อในอนาคต หรือจะ Export ใหม่ที่หลังก็ได้ครับ
ก็ถือว่าเล่าสู่กันฟังกับประสบการณ์ในการดีลกับข้อมูลเยอะๆ เผื่อเป็นทางเลือกหนึ่งในการใช้งาน Cloud สำหรับการประมวลผลข้อมูล ซึ่งจริงๆยังมี feature อื่นๆอีกเยอะมากของ Google Cloud ในเชิง Data Analytic หรือ BI ซึ่งเอาตรงๆ ผมก็เพิ่งมาลองเล่นเมื่อเดือนที่แล้วนี้เอง ถ้าไว้ลองเล่น feature อื่นๆเพิ่มแล้วจะมาเล่าสู่กันฟังอีกรอบครับ ตอนนี้ขอตัวไปแพ้คปลาเก๋า เอ้ยยย กระเป๋าก่อน แล้วเจอกันใหม่บทความหน้าครับ
ข้อมูลเพิ่มเติม [Google Cloud BigQuery]